Member-only story
Text Classification with Large Language Models (LLMs)
Like many individuals today, I find myself integrating AI into various aspects of my daily routine. The versatility and capabilities of AI have made it an indispensable tool in numerous applications, from automating simple tasks to providing insightful analysis. Recently, I’ve been exploring the potential of Large Language Models (LLMs) and came across an intriguing idea: using LLMs for classification tasks.
Classification, for those unfamiliar, involves labeling or categorizing data into different groups. This labeled data set is used to train AI models. It’s a basic task in NLP and has numerous applications — one of which is training these Large Language Models.
Text classification can be challenging when dealing with unstructured data. Given a general understanding of the world, I thought it was possible to do so using LLMs. To verify my theory, I conducted a small proof of concept (POC) to determine its feasibility and to identify any potential issues.
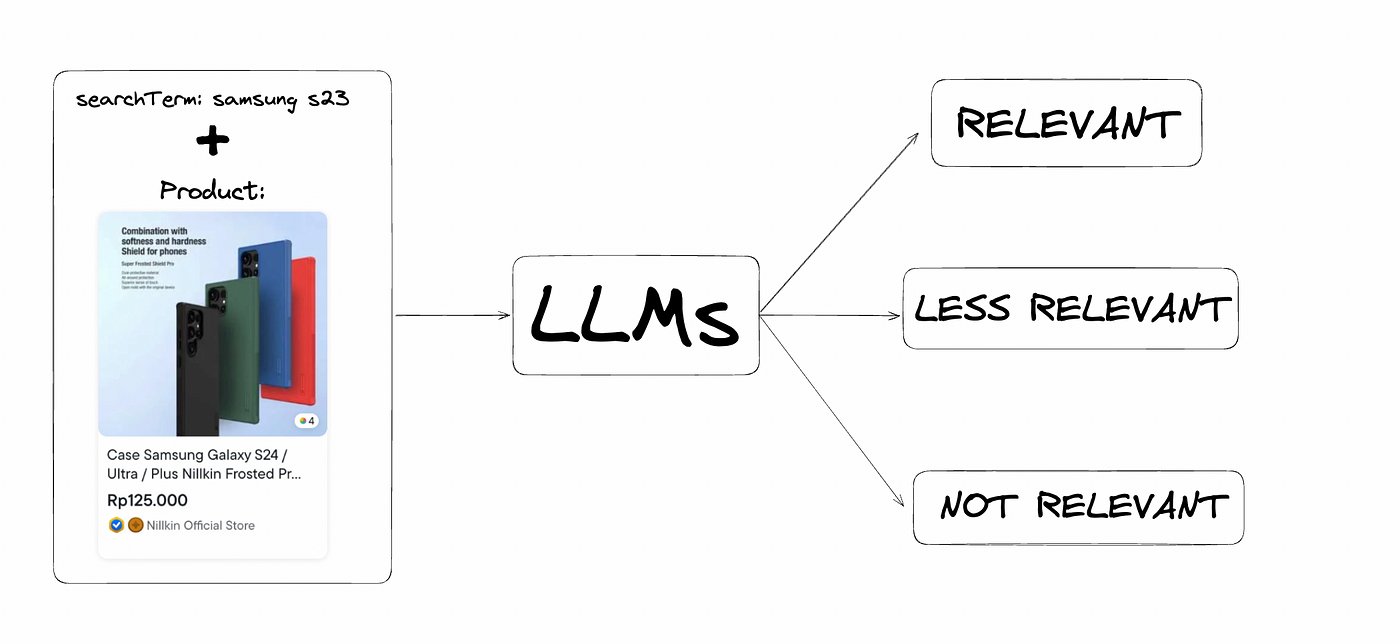
As a relevance engineer in the e-commerce sector, I decided to classify products for a search term into three categories: Relevant, Less Relevant, and Not Relevant.
For example, if you search for “Apple iPhone 15,” you’ll see results like “iPhone 15,” “iPhone 15 Pro,” and “iPhone 13.” While “iPhone 15” is relevant to the search term, “iPhone 15 Pro” is less so due to a model mismatch. “iPhone 13,” however, is not relevant at all. Typically, this kind of classification requires manual effort.
Prerequisites:
Before diving into the Python script, let’s go through the prerequisites. Here are the steps I followed to ensure everything runs smoothly:
- Environment Setup: To manage dependencies and versions more efficiently, I used Conda. It simplifies the process and helps avoid conflicts.
- Cost-Effective Models: Working within a limited budget, I opted for cost-effective solutions like Ollama and local models such as Llama 3 and Mistral LLMs. These models provide robust performance without incurring high costs.
- Code Editor: I used Visual Studio Code to write the Python code. Its powerful features and extensions make it an excellent choice for coding and debugging.